
Introduction
Voice AI is no longer optional for competitive customer engagement in 2026, the TTS API powering it determines whether your product earns trust or loses users mid-conversation. A recent analysis shows delays exceeding 600ms degrade user trust, while pauses over 1,000ms trigger call abandonment rates above 40%.
Choosing the right TTS API for voice AI integration means applying different criteria than you'd use for narration or content production. Real-time dialogue has tighter requirements:
- Streaming output : audio must begin before full synthesis completes
- Sub-200ms time-to-first-audio : the threshold for natural-feeling turn-taking
- Language and accent breadth : especially critical for pan-India or multilingual deployments
- Pipeline compatibility : seamless handoffs between STT, LLM, and TTS components
Key Takeaways
- TTS APIs convert text to natural-sounding speech; voice AI requires streaming output and sub-200ms latency
- Top picks for 2026: ElevenLabs, OpenAI TTS, Deepgram Aura, Google Cloud TTS, and Cartesia, each built for different use cases
- Key evaluation criteria: time-to-first-audio, voice naturalness, language coverage, SSML support, and per-character cost at scale
- Conversational agents require sub-200ms latency; IVR and narration workflows can trade speed for higher voice quality
- Pricing ranges from ₹332 (≈ $4)to ₹24,900 (≈ $300)per 1M characters depending on provider and plan tier
What Is a TTS API and Why Does It Matter for Voice AI?
A TTS API is a service that accepts text input and returns synthesized audio, delivered either as a batch file or real-time stream over HTTP or WebSocket connections. Modern neural TTS models have replaced older concatenative systems that stitched together pre-recorded segments.
The quality gap has closed fast. Neural architectures like Google's WaveNet cut the difference between machine and human speech by over 50%, while Tacotron 2 achieves a Mean Opinion Score (MOS) of 4.53 nearly indistinguishable from professionally recorded human speech at 4.58.
TTS quality directly determines whether a voice AI interaction feels credible. Even a perfectly reasoned response loses trust if the voice is robotic or the delivery is slow.
Research shows that delays under 400ms feel genuinely responsive, but once pauses regularly exceed 600ms, interactions feel unnatural. When latency crosses 1,000ms, users assume connection failure, pushing abandonment rates above 40%.
The Voice AI Pipeline
The typical voice AI architecture follows this sequence:
- Speech-to-Text (STT) : Captures and transcribes user speech
- Large Language Model (LLM) : Processes intent and generates response text
- Text-to-Speech (TTS) : Converts response text to natural audio
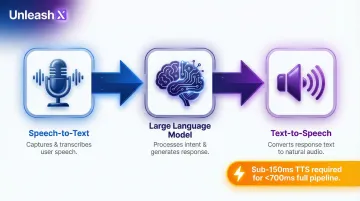
For voice AI agents handling real-time conversations (as opposed to narration tools), critical metrics shift toward streaming time-to-first-audio, interruption handling, and concurrent session support. Production voice AI systems requiring sub-700ms full-pipeline response times need TTS layers delivering first audio in under 150ms, a threshold only a subset of providers meet reliably.
Best TTS APIs for Voice AI Integration in 2026
These five APIs were evaluated on latency, voice naturalness, multilingual coverage, developer experience, and suitability for production voice AI workloads.
ElevenLabs
ElevenLabs is a leading AI voice platform widely used for benchmark-quality voice synthesis. It offers hundreds of voices, advanced voice cloning, and a multilingual model supporting 32 languages making it popular for voice AI products demanding expressive, human-like output.
Why it stands out: The Turbo v2.5 model delivers 75ms model inference latency suited to conversational AI, alongside voice cloning that lets teams build consistent branded voices with minimal sample audio. It sets the quality bar that other providers are measured against.
| Feature | Details |
|---|---|
| Key Features | Streaming TTS, voice cloning, emotion/style controls, SSML support, 32 languages, Flash v2.5 low-latency model |
| Pricing | Starter: ₹415 (≈ $5)/month for 30,000 credits (0.5-1 credit per character); Creator: ₹913 (≈ $11)/month for 100,000 credits; effective cost up to ₹24,900 (≈ $300)per 1M characters for overages |
| Concurrency Limits | Free: 4 concurrent requests; Starter: 6; Creator: 10 for Flash/Turbo models |
| Best For | Conversational AI agents, branded voice products, audiobook narration requiring high realism |
Important consideration: While ElevenLabs delivers exceptional voice quality, strict concurrency caps (10 concurrent requests on Creator tier) require Enterprise negotiations for high-volume contact centers.
OpenAI TTS
OpenAI's TTS API is part of the broader OpenAI platform ecosystem, offering six preset voices and multi-language support powered by GPT-4-class models. It's particularly well-suited for teams already building LLM-driven voice agents within the OpenAI stack, enabling tight integration between reasoning and speech output.
Where it earns its place: The Realtime API supports speech-to-speech sessions with sub-500ms response capability for low-latency agent use cases. Style prompting lets developers influence tone without manual SSML using natural language instructions like "speak in a cheerful and positive tone" which lowers the barrier for non-specialist developers.
| Feature | Details |
|---|---|
| Key Features | 6 preset voices, multi-language, style prompting via natural language, Realtime API for speech-to-speech sessions, tool-calling support |
| Pricing | Standard tts-1: ₹1,200 (≈ $15)per 1M characters; tts-1-hd: ₹2,500 (≈ $30)per 1M characters; Realtime API: ₹5,300 (≈ $64)per 1M audio output tokens (gpt-realtime-1.5), ₹1,700 (≈ $20)per 1M tokens (gpt-realtime-mini) |
| Latency | Standard TTS: ~200ms TTFA; Realtime API: ~500ms time-to-first-byte for US clients |
| Best For | Teams building within the OpenAI ecosystem; real-time voice agents combining LLM reasoning with speech output |
Trade-off: OpenAI's Realtime API bundles STT, LLM, and TTS into a single WebSocket with token-based pricing, simplifying architecture but offering less granular control than specialized TTS providers.
Deepgram Aura
Deepgram is primarily known for its widely benchmarked speech recognition (STT), but its Aura TTS model is built specifically for real-time voice agent pipelines. Pairing it with Deepgram's STT in a unified pipeline reduces integration complexity for teams building bidirectional voice experiences.
The core advantage: Aura's architecture is optimized for time-to-first-audio in streaming scenarios, achieving sub-200ms baseline TTFB with optimized performance reaching 90ms. A single SDK covering both STT and TTS reduces vendor count and eliminates latency hops in a production voice AI stack.
| Feature | Details |
|---|---|
| Key Features | Streaming-first TTS, unified STT+TTS SDK, 90ms optimized TTFB, WebSocket support, 200+ free trial credits |
| Pricing | ₹2,500 (≈ $30)per 1M characters (Pay As You Go); ₹2,200 (≈ $27)per 1M characters (Growth tier); ₹16,600 (≈ $200)free credit for new users |
| Concurrency | 45-60 concurrent requests (REST + WebSocket) on standard plans; 150+ WebSocket connections supported |
| Best For | Real-time voice agents and call automation where low latency and unified speech stack are priorities |
Practical advantage: Deepgram's unified platform eliminates the complexity of coordinating multiple vendor APIs, making it ideal for teams prioritizing development speed and architectural simplicity.
Google Cloud Text-to-Speech
Google Cloud TTS is one of the most established TTS APIs in the market, offering 380+ voices across 75+ languages and dialects, including WaveNet, Neural2, and Studio neural voice models. It's backed by Google's pan-India infrastructure, making it a reliable choice for high-volume, multilingual deployments.
Differentiator: Google's Neural2 and Studio voices deliver strong naturalness with comprehensive SSML support for fine-grained prosody control. Its breadth of language and dialect supportincluding Hindi, Tamil, Telugu, Bengali, Kannada, and Malayalam makes it one of the most practical options for across India deployed voice AI applications or those targeting South Asian markets.
| Feature | Details |
|---|---|
| Key Features | 380+ voices, 75+ languages including 6+ Indian languages, WaveNet/Neural2/Studio tiers, SSML support, streaming capability, generous free tier |
| Pricing | Standard: ₹332 (≈ $4)per 1M characters; WaveNet/Neural2: ₹1,300 (≈ $16)per 1M characters; Studio: ₹13,300 (≈ $160)per 1M characters; Free tier: 4M characters/month (Standard), 1M characters/month (Neural2/Studio) |
| Best For | Multilingual voice AI, pan-India-scale deployments, enterprise applications requiring broad language/dialect coverage including Indian languages |
Cost efficiency: Google Cloud TTS offers the most competitive pricing for high-volume deployments, with Standard tier pricing at just ₹332 (≈ $4)per 1M characters 75x cheaper than premium ElevenLabs overages.

Cartesia
Cartesia is a newer entrant that has gained rapid adoption among voice AI developers for its ultra-low-latency Sonic model. It uses state-space model (SSM) architecture rather than transformer-based TTS to achieve time-to-first-audio in the 40–90ms range among the fastest in the market.
Where speed becomes the differentiator: Cartesia's primary edge is raw speed. Its latency profile makes it viable for sub-100ms conversational turn-taking the threshold where voice AI starts to feel genuinely natural rather than like a system responding to a prompt.
It also supports emotional expression including laughter, making voices more human in spontaneous interactions.
| Feature | Details |
|---|---|
| Key Features | Sub-100ms time-to-first-audio (40ms Turbo, 90ms Sonic-3), emotional expression controls, 15+ languages, WebSocket streaming, state-space model architecture |
| Pricing | Credit-based: 1 credit per character; Pro: ₹332 (≈ $4)/month for 100K credits; Startup: ₹3,200 (≈ $39)/month for 1.25M credits; effective cost ₹2,600 (≈ $31)-40 per 1M characters |
| Concurrency | 15 TTS requests (Scale tier); WebSocket connections limited to 10X concurrency (150 connections for Scale) |
| Best For | Ultra-responsive real-time voice agents where conversation latency is the primary constraint |
Architectural advantage: SSM architecture scales linearly rather than quadratically, enabling Cartesia to maintain consistent latency under concurrent load where transformer-based models degrade.
How We Chose the Best TTS APIs for Voice AI
Unlike general TTS comparisons, this list was evaluated specifically through the lens of Voice AI integration meaning metrics like batch audio quality matter less than streaming time-to-first-audio, interruption handling, WebSocket stability, and concurrent session throughput.
Evaluation Criteria
1. Latency
Vendor-claimed inference speeds (40ms or 75ms) rarely reflect real-world Time-to-First-Audio. Network overhead pushes actual TTFA into the 150–500ms range. We prioritized providers with consistent sub-200ms TTFA in production environments.
2. Voice Naturalness
Quality was evaluated using Mean Opinion Score (MOS) protocols scores of 4.3–4.5 indicate excellent quality rivaling human speech. We focused on conversational prosody, not narration quality, since dialogue demands different rhythm and pacing.
3. Language and Dialect Depth
Coverage was assessed by dialect quality, not just language count. Google Cloud TTS leads on Indian language support (Hindi, Tamil, Telugu, Bengali, Kannada, Malayalam), while most other providers offer limited or no regional dialect coverage.
4. Developer Experience
Deepgram's unified STT+TTS SDK reduces vendor coordination overhead, while OpenAI's natural language prompting eliminates SSML complexity. We evaluated documentation clarity, error message quality, and WebSocket stability under load.
5. Pricing at Scale
Effective costs range from ₹332 (≈ $4)per 1M characters (Google Cloud Standard) to ₹24,900 (≈ $300)per 1M characters (ElevenLabs premium overages). At 100M characters monthly, that's a ₹33,200 (≈ $400)vs. ₹24.9 lakh (≈ $30,000)gap, a 75x cost divergence that grows fast.
Common Mistakes Developers Make
- Choosing based on demo quality rather than streaming latency, the voice that sounds best in a 30-second clip may not stream fast enough for real-time conversation. Always test under realistic network conditions.
- Ignoring concurrency limits ElevenLabs caps standard tiers at 15 concurrent requests; Deepgram supports 150+ WebSocket connections. Production systems handling 100 simultaneous calls will hit 429 errors without Enterprise SLAs or connection pooling.
- Skipping SSML and interruption support conversational flow requires barge-in handling mid-sentence. Providers without SSML break tags or barge-in events will break dialogue naturalness.
- Underestimating cost divergence ₹1 (≈ $0.015)vs. ₹2 (≈ $0.030)per 1K characters looks trivial until you're processing 100M characters monthly. That's ₹1.2 lakh (≈ $1,500)vs. ₹2.5 lakh (≈ $3,000)every month.
- Overlooking the streaming accuracy tradeoff streaming TTS operates with 5–20x less context than batch processing, raising pronunciation failure rates on alphanumeric IDs, phone numbers, and addresses. Never use streaming TTS for critical data readouts without validation.

The Production Benchmark
For production voice AI systems requiring sub-700ms full-pipeline response (STT + LLM + TTS), the TTS layer must deliver first audio in under 150ms. Only three providers consistently meet this threshold: Cartesia (40–90ms), ElevenLabs Flash v2.5 (75ms model latency), and Deepgram Aura (90ms optimized).
Systems like UnleashX's AI employees are built around this exact constraint targeting under 700ms end-to-end latency across voice, chat, and task execution, with 99% uptime and support for 100+ languages including 12+ Indian vernaculars.
Conclusion
The best TTS API for Voice AI in 2026 is the one that fits your latency requirements, language coverage needs, and production budget not the one with the flashiest demo. Vendor choice should follow use case, not reputation.
Here's how the leading options stack up by use case:
- Ultra-low latency agents: Cartesia and Deepgram Aura deliver the fastest streaming performance
- Multilingual deployment across Indias: Google Cloud TTS offers the broadest language coverage at competitive pricing
- OpenAI-native teams: The Realtime API reduces architectural complexity
- Premium voice quality and cloning: ElevenLabs sets the standard
Test APIs under realistic load, not just demo conditions, and evaluate total pipeline latency (STT + LLM + TTS) before committing. Performance differences compound across the full call cycle.
Ready to skip the API evaluation entirely? UnleashX's AI employees come production-ready with voice AI fully integrated, deployable in 45 minutes, supporting 100+ languages and 12+ Indian languages, with <700ms latency and 99% uptime out of the box. Get in touch via WhatsApp to see them in action.
Frequently Asked Questions
What is the difference between a TTS API and a Voice AI API?
A TTS API converts text to audio output (one component in a pipeline), while a Voice AI API typically refers to a full speech-to-speech or agent stack that includes STT, LLM reasoning, and TTS together. Most production voice AI systems compose multiple APIs rather than relying on a single one.
How do AI voice agents handle Hindi and regional languages for Indian customers?
Modern voice AI platforms support natural conversations in Hindi, Tamil, Telugu, Kannada, Marathi, Bengali, and code-mixed Hinglish. UnleashX voice agents detect caller language automatically, switch mid-call where needed, and integrate with WhatsApp for follow-ups, which matches how Indian buyers in BFSI, real estate, and D2C actually engage.
Which Indian companies are deploying AI voice agents in production?
Indian BFSI majors (HDFC, ICICI, SBI, Axis), real estate firms, lending NBFCs, and D2C brands are running voice AI in production for sales calls, KYC follow-ups, and customer support. NASSCOM has tracked rapid adoption across IT services and BPO firms (TCS, Infosys, Wipro, HCLTech) building voice AI practices for Indian and pan-India enterprise clients.
Can TTS APIs support Indian languages for voice AI agents?
Google Cloud TTS offers the broadest Indian language coverage (Hindi, Tamil, Telugu, Bengali, Kannada, Malayalam), while most other providers have limited or no Indian dialect support. Indian language quality varies significantly between providers real-world testing in your target dialect is essential.
What Indian regulations should I consider before deploying voice AI?
DPDP 2023 governs personal data handling in voice interactions, including consent capture and audit trails. RBI guidelines on outsourcing apply to BFSI deployments, IRDAI rules cover insurance workflows, and TRAI's commercial communication rules govern outbound calling. Production-grade voice AI platforms maintain call recordings, language logs, and consent receipts to meet these requirements.
What is time-to-first-audio and why is it the key latency metric for voice agents?
Time-to-first-audio measures how quickly an API begins streaming audio after receiving text. This metric, not total audio generation time, determines whether a voice agent feels natural or sluggish to the end user.
Want to see how UnleashX AI Employees can transform your business? Visit UnleashX to explore the full platform and book a personalized demo.


